Table of contents
Toggle TOC
Prologue
Update (2025-12-15): The project has evolved. Hoarder is now officially Karakeep (server-side), with a beautiful third-party iOS/Safari companion named Karakeeper. This post has been fully aligned with the new image names, configuration patterns, and a critical deep-dive into the security setting
CRAWLER_ALLOWED_INTERNAL_HOSTNAMES—a must-know for anyone behind a complex network setup.In an era of informational deluge, most digital hoarders eventually face a structural crisis. For a long time, Cubox was my lighthouse. Yet, its growing weight and opaque boundaries eventually made me crave something closer to the source: an open-source sanctuary I could call my own.
The Breaking Point with Cubox
For the uninitiated, Cubox is a popular comprehensive “read-it-later” service developed in China. It’s sleek, packs powerful parsing capabilities, and offers seamless sync across Apple & Android ecosystems. Think of it as a localized, feature-rich alternative to Pocket or Instapaper. However, its origin story comes with strings attached that eventually became deal-breakers for me.
-
The Privacy Shadow: Data Sovereignty vs. State Compliance
Content curation is deeply personal, but in the specific context of the Chinese internet, it’s also political. Cubox operates two segregated versions: an international version (
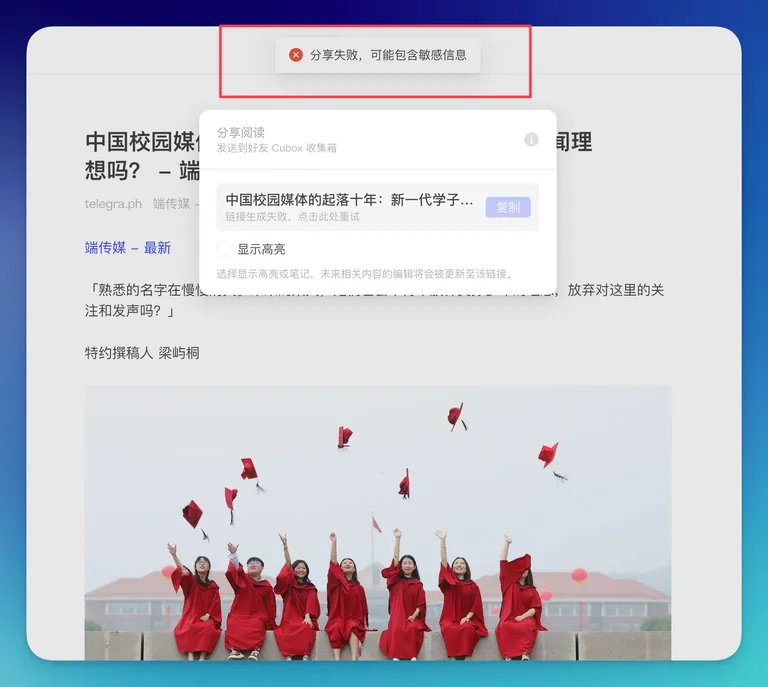
cubox.cc) and a mainland domestic version (cubox.pro). Due to strict local cybersecurity laws, the domestic version is subject to rigorous content compliance and censorship mechanisms.This isn’t theoretical. Usage is shadowed by the constant risk of “Force Majeure”—a common euphemism in Chinese tech for government-mandated censorship. I’ve personally encountered situations where clipped articles (captured for private archival) were flagged and rendered “unshareable” or inaccessible because they triggered sensitive keyword filters.
The screenshot below illustrates this reality: a generic error message blocking content distribution due to “uncontrollable factors.” For an archivist, this is the ultimate betrayal. If your digital memory can be redacted by an algorithm adhering to state policy, you don’t own your data—you are merely renting a view.
-
The Subscription Tax
Cubox’s free tier, capped at a mere 200 items, feels like a restricted demo. Stepping up to VIP demands ¥198/year. While reasonable for some, for those of us who have already invested in a NAS, paying a recurring fee for storage we already own feels like a redundancy. In a tightening economy, frugality is a virtue.
-
Death by a Thousand Features
Cubox began as a blade, sharp and focused. But complexity crept in—AI summaries and highlighting tools that I never asked for. To me, a clipper is a “digital hoarder’s junk drawer”—a local, immutable archive to prevent the sting of broken links. Simplicity isn’t just a choice; it’s a discipline. Driven by the philosophy of “Entia non sunt multiplicanda praeter necessitatem” (Occam’s Razor), it was time to trim the fat.
The Blueprint: Self-Hosting Guide
Karakeep (the soul formerly known as Hoarder) is alive on GitHub. If you’re migrating, check the official notes. For platform-specific walkthroughs like Synology, the community guides at NasDaddy are excellent companions.
I recommend the Docker route for its isolation and elegance.
Here’s the refined docker-compose.yml:
version: "3.8"
services:
web:
image: ghcr.io/karakeep-app/karakeep:${KARAKEEP_VERSION:-release}
restart: unless-stopped
volumes:
- data:/data
ports:
- 3000:3000 # Map to your port of choice
env_file:
- .env
environment:
REDIS_HOST: redis
BROWSER_WEB_URL: http://chrome:9222
MEILI_ADDR: http://meilisearch:7700
# Specifically allow the crawler to access domains resolving to internal/loopback IPs.
CRAWLER_ALLOWED_INTERNAL_HOSTNAMES: "."
redis:
image: redis:7.2-alpine
restart: unless-stopped
volumes:
- redis:/data
chrome:
image: gcr.io/zenika-hub/alpine-chrome:124
restart: unless-stopped
command:
- --no-sandbox
- --disable-gpu
- --disable-dev-shm-usage
- --remote-debugging-address=0.0.0.0
- --remote-debugging-port=9222
- --hide-scrollbars
meilisearch:
image: getmeili/meilisearch:v1.13.3
restart: unless-stopped
env_file:
- .env
environment:
MEILI_NO_ANALYTICS: "true"
volumes:
- meilisearch:/meili_data
volumes:
meilisearch:
data:
redis:The heart of the configuration lies in the .env file. Docker Compose requires you to create this manually to inject the variables into the service lifecycle:
KARAKEEP_VERSION=release
NEXTAUTH_SECRET=your_random_secret_here
MEILI_MASTER_KEY=your_random_key_here
NEXTAUTH_URL=http://localhost:3000 # Your public-facing URL or local address
## Intelligence Layer (Optional)
OPENAI_BASE_URL=https://xxx.com/v1
OPENAI_API_KEY=sk-your-key
INFERENCE_LANG=en
INFERENCE_TEXT_MODEL=qwen2-72b-instruct # I personally find qwen2-72b remarkably sharp for taggingDecoding CRAWLER_ALLOWED_INTERNAL_HOSTNAMES (Security Insights)
Karakeep’s workers are curious; they initiate outbound requests to capture the web. To prevent SSRF (Server-Side Request Forgery), Karakeep acts as a gatekeeper, blocking any request that resolves to a private or loopback IP.
- The Tightening of the Net: Since
v0.28.0, SSRF protection has become much stricter. Requests reaching toward internal IPs are dropped by default unless whitelisted. - The Mainland Context: In environments utilizing “Transparent Proxy / Fake-IP DNS” setups (common in China), certain domains might resolve to private addresses during the redirection dance. A crawler unaware of this will see an “internal IP” and refuse to move.
- The Shortcut: Setting
CRAWLER_ALLOWED_INTERNAL_HOSTNAMESto.is the universal bypass—handy for resolving reachability issues, though it should be used with an understanding of your network boundaries.
The Karakeep Edge
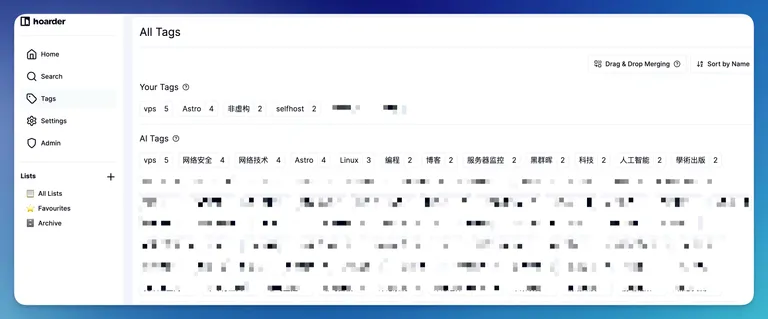
AI-Assisted Serendipity
For the “passive hoarder,” this is the killer feature. You don’t have to agonize over taxonomy. The AI observes the content and applies tags that facilitate discovery without the friction of manual curation.
Room for Growth
The Snapshot Silo
Karakeep’s snapshots are currently tucked away in proprietary .db formats. To truly fulfill the promise of local archival, I’d hope for a shift toward universal formats—pure .html or high-fidelity .png captures that survive even if the software doesn’t.
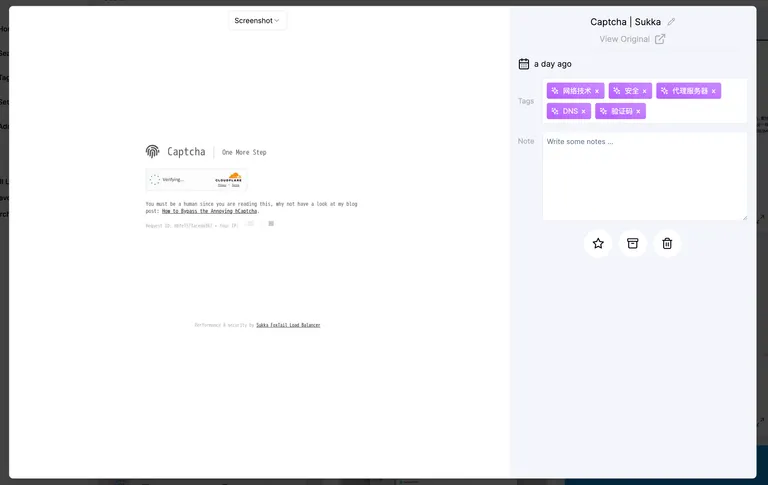
The Cloudflare Wall
Because Karakeep relies on a headless Chrome instance to simulate human presence, it occasionally hits the “Cloudflare Turnstile” barrier. High-security blogs might occasionally slam the door on the crawler, leaving you with a capture of a challenge page rather than the wisdom you sought.